Разработка метода анализа тенденций развития Интернет
Elaboration of a method for analyzing Internet evolution
Куликовская А. А.
НИЦ Курчатовский институт, ИТЭФ, Москва
Аннотация
В данной статье рассматривается алгоритм, определяющий наиболее часто используемые термины и ключевые фразы в названиях статей популярны научных журналов. Был проведен анализ всех статей на сайтах издательств
за последние 5 лет. На основе собранной статистики были выбраны наиболее часто употребляющиеся термины в названиях статей. Учитывая даты написания статей и изменения их количества можно сделать выводы о том,
в каких категориях на данный момент ведутся активные разработки, а какие темы сейчас являются менее обсуждаемыми.
This article is devoted to the created algorithm which determines the most frequently used terms and key phrases in the titles of articles popular in scientific journals. An analysis of all the articles on the
websites of publishers over the past 5 years was carried out. Based on the collected statistics, the most frequently used terms in the titles of articles were chosen. Considering the dates of writing articles
and changes in their number, conclusions can be drawn about in which categories active development is currently being conducted, and which themes are now less discussed.
Введение
В настоящее время темп роста объемов данных стал таким, что человеку уже стало невозможно все прочесть и проанализировать (эффект big data) всю информацию по интересующей теме, это делает компьютерную аналитику
найденных материалов безальтернативной. Если брать в расчет только базу данных Scopus, то в ней представлено 220 журналов с открытым доступом с тематикой: Computer Science. Всего на сайте представлено
1 798 журналов с той же тематикой. В списке научных журналов ВАК содержится 329 журналов, в которых есть 05.13.00 – информатика, вычислительная техника и управление (научные специальности и соответствующие
им отрасли науки).
В среднем, в каждом журнале 8 статей и Большинство журналов выходит ежемесячно.
Итого, не считая депозитарии и прочие источники с научными публикациями, 146 статей в день, это только открытые источники, в которых есть тема IT.
При всем желании мы сможем изучить только малую часть этого количества. И не обязательно это будет наиболее значимая часть, по которой можно будет сделать однозначный вывод обо всех остальных статьях.
Один из возможных вариантов решения этой задачи — это анализатор, который позволяет фильтровать и предлагать пользователям только те статьи, которые удовлетворяют заданным критериям.
На основе большого количества статистических данных предполагается делать некоторые аналитические выводы. В данной работе это определение наиболее актуальных тем среди исследуемых.
Цель исследования
Создание фильтра для определяющий наиболее часто используемые термины и ключевые фразы в названиях статей популярных научных журналов. Получение вывода о развитии IT направлений
на основе наиболее повторяющихся научных терминов в названиях статей. Работа состоит из следующих частей:
- В первом разделе описывается создание программных модулей, выполняющих парсинг сайтов издательств для поиска и скачивания оглавлений журналов, поиск даты написания статьи и создание программного модуля,
распределяющего все статьи в базу данных, где помимо названия содержится также информация о журналах и о дате выхода статей
- Во втором разделе описывается метод оценки количества наиболее повторяющихся терминов в названиях статей, написанных за все годы и за каждый год в отдельности.
- В третьем разделе производится сравнение результатов статистического анализа количества статей и определение основных направлений развития технологий Интернет и тенденций последних лет.
- В заключении подводятся итоги сравнения и намечаются задачи для дальнейших исследований.
Программное обеспечение и банк данных
В качестве банка данных использовались англоязычные журналы на сервере www.sciencedirect.com/journal.
На данный момент количество статей составляет 32000. Общее направление статей – Computer Science.
Созданные модули – это программы на языке Python 3.7, которые работают последовательно, независимо друг от друга.
База данных для хранения информации – PostgreSQL.
Cоздание программных модулей
Отбор и загрузка статей осуществляется с помощью составления регулярных выражений, для поиска ссылок на статьи и заданных ключевых слов в названиях статей.
После загрузки все названия статей, год выпуска были сохранены в текстовый файл, а оттуда автоматически загружены в базу данных, где также представлена информация о журнале, в котором опубликована каждая статья.
Список журналов, которые были скачаны для анализа данных находятся в приложении 1.
Метод оценки количества терминов
Создаются несколько текстовых файлов, в каждом из которых содержаться только названия статей за определенный год. В этих файлах производится поиск наиболее часто повторяющихся слов.
Это делается с помощью программного модуля на языке python, однако далее в ручном режиме оттуда удаляются частицы, предлоги, глаголы, прилагательные и слова не несущие смысла
в отдельности от других слов, происходит суммирование однокоренных существительных в разных формах, для исключения повторов.
Список 50 наиболее повторяющихся слов в промежутке с 2015-2019гг. находится в приложении 2.
Из наиболее повторяющихся слов интерес представляют следующие слова:
fuzzy logics, big data, computer learning, computer modeling, cloud, recognition, wireless
На рисунке 1 представлено относительное изменение количества статей, содержащих данные слова в период с 2015 по 2019 года.
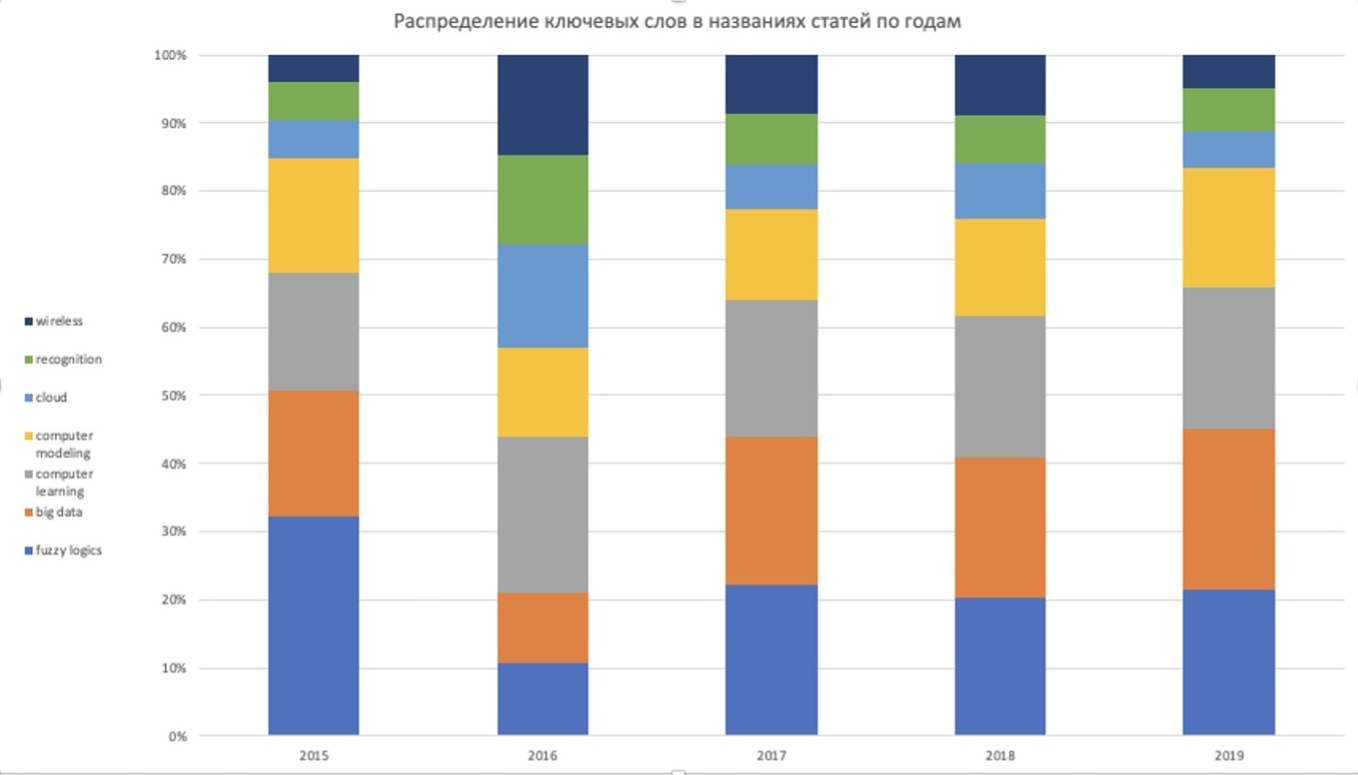
Рис. 1. Количество статей, вышедших за все годы в каждой из категорий
Для анализа более продолжительного участка времени выбраны следующие ключевые слова: recognition, big data.
Статьи с этими словами были отслежены с 1996 года. Результат относительного соотношения количеств статей с данными словами на рисунке 2.
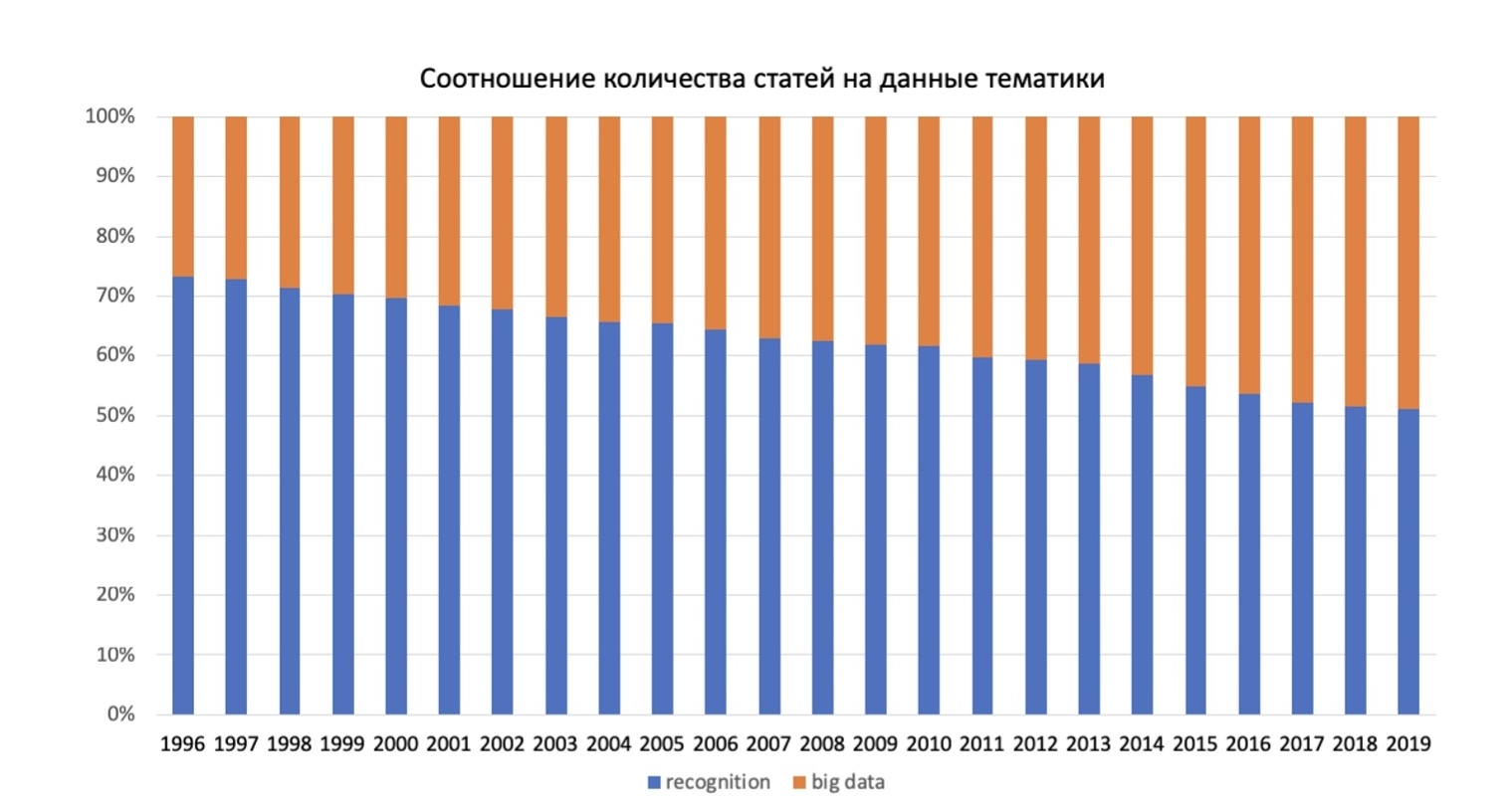
Рис. 2. Cоотношения количества статей со словами recognition и big data
Сравнение результатов статистического анализа
На основе полученных данных о количестве статей в каждой категории, за каждый год в отдельности, можно оценить динамику изменения процентного соотношения количества статей.
Можно заметить, что какие-то категории со временем становятся более популярными, например “Big data ”, а категория “ recognition” становится менее актуальной.
Заключение
В автоматическом режиме определены наиболее развивающиеся направления технологий Интернет и те направления, которые уже достигли своего решения.
Данный метод анализа развития можно применять не только на выбранной тематике, но и других направлениях развития науки и технологии. Комбинируя банки данных, категории и критерии
отбора можно получить наиболее актуальные на данный момент направления в любой отрасли.
В данной работе рассматривались только статьи с выбранного сайта, поэтому информация, полученная в данном исследовании, может отличаться от других источников. Однако при дальнейшем масштабировании
исследования данные будут более точными.
Приложение 1. Список журналов, выбранных для анализа
Computer Speech & Language 22/323
Journal of Systems and Software 148/964
Fuzzy Sets and Systems 85/1040
information and Software TechnologyI 96/665
Information Systems 35/433
Computers & Security 218/670
International Journal of Human-Computer Studies 35/431
Semantic Web 9/162
Engineering Applications of Artificial Intelligence 123/897
Information and Management 41/464
neurocomputing 753/5404
Computer Communications 154/806
Telematics and Informatics 74/617
The Journal of Strategic Information Systems 4/129
Journal of Network and Computer Applications 737/2308
Applied Soft Computing 341/2869
Future generation computer systems 603/1889
Artificial Intelligence 21/390
Information Sciences 789/6681
Expert Systems with Applications 302/3373
Theoretical Computer Science 79/1668
Приложение 2. Список 50 наиболее повторяющихся слов в промежутке с 2015-2019гг.
networks 2936; recognition 706; clustering 706;
dynamic 694; wireless 682; framework 678;
machine 665; time 664; design 655;
search 649; software 637; cloud 635;
decision 626; algorithms 625; sensor 618;
distributed 613; robust 607; algorithm 2374;
big data 2066; systems 1996; learning 1914;
approach 1840; analysis 1683; network 1682;
neural 1597; model 1584; optimization 1535;
editorial 1504; system 1464; board 1462;
control 1390; detection 1198; classification 1175;
method 1068; adaptive 1014; information 949;
hybrid 907; image 892; social 866;
selection 858; from 835; application 835;
via 801; problem 761; efficient 752;
new 751; feature 741; novel 725;
mobile 720; study 715;
| 








