| ||
 |
 |
 |
 |
 |
 |
 |
 |
 |
|
Новый протокол TCP Современная версия протокола ТСР (RFC-793, -1323) имеет ряд недостатков (см. http://book.itep.ru/4/44/tcp_443.htm, а также RFC-2525 или [1]):
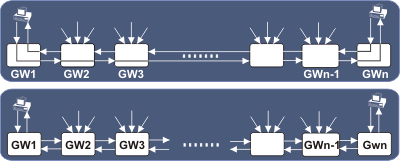
Попытки адаптировать действующую версию протокола имели существенный, но ограниченный успех (модели Tahoe, Reno (см. также RFC-2582), Vegas, Т/ТСР (см. RFC-1644), SACK (см. RFC-2018, -2883, -3517) и другие (см., например, RFC-2309, -3042, -3168)). Некоторые недостатки были частично устранены (синдром узкого окна, алгоритм Нагля). Следует, впрочем, заметить, что радикальные изменения протокола ТСР не предпринимались неслучайно. Программные продукты, используемые на сотнях миллионов ЭВМ не поменять в одночасье. И нужно искать решение, которое позволяло бы работать со старыми версиями программного обеспечения, базирующегося на традиционном протоколе ТСР. В данной статье предлагается принципиально иная модель таботы транспортного протокола ТСР (NTCP). В запросе SYN этого протокола должен присутствовать код опции NTCP (код поля опции вид может равняться, например, 20) и, если поддерживающий NTCP объект получает такой сегмент, он должен послать соответствующий отклик отправителю. Сначала рассмотрим, что мешает традиционному ТСР работать в сверхскоростных каналах. Здесь наиважнейшими параметрами являются window > RTT ×B/MSS и поле идентификатора пакета, где В - полоса пропускания канала, измеряемая в битах в сек, максимальный размер сегмента MSS здесь и далее задан в битах), а RTT-сумма времен доставки сегмента от отправителя до получателя и отклика от получателя до отправителя. По умолчанию величина MSS равна 1460*8 = 11680бит. О проблеме работы протокола ТСР в режиме больших произведений RTT на В см. [2]. Высокопроизводительные каналы (³1 Гбит/с) уже сегодня могут исчерпать разнообразие идентификационных кодов пакетов за один сеанс связи. Появление же двух пакетов с равными идентификаторами может породить неразрешимые трудности. Для передачи мегабайтного файла по гигабитному каналу требуется около 40 мсек (при этом предполагается, что задержка в канале составляет 32 мсек (RTT=64 мсек)). Собственно передача этой информации занимает 8 мсек. Из этих цифр видно, что традиционные протоколы, размеры окон и пр. могут свести на нет преимущества скоростного, дорогостоящего канала. Пропускная способность такого канала определяется уже не его полосой, а задержкой. Понятно также, что необходимо расширить эффективное поле размера окна с 16 до 32 бит (это делается сегодня с привлечением опции ТСР). Чтобы не изменять формат TCP-сегментов, можно сделать код размера окна в программе 32-разрядным, сохранив соответствующее поле в сегменте неизменным (см. RFC-2414, -2415). Размер окна в этом случае задается как бы в формате с плавающей запятой. При установлении канала определяется масштабный коэффициент n (порядок) лежащий в интервале 0-14. Передача этого коэффициента (один байт) осуществляется сегментом SYN в поле опций. В результате размер окна оказывается равным 65535*2n. Если один из партнеров послал ненулевой масштабный коэффициент, но не получил такого коэффициента от своего партнера по каналу, то n считается равным нулю. Эта схема позволяет сосуществовать старым и новым системам. Выбор n возлагается на TCP-модуль операционной системы. Увеличение размера окна в свою очередь приводит к проблемам, возникающим при перегрузке. Каноническое поведение протокола TCP в случае потери пакета (это может быть сегмент данных или отклик) заключается в повторной пересылке всех посланных пакетов, начиная с потерянного. Если считать, что о потере пакета отправитель узнает в среднем спустя RTT/2, то для рассмотренного выше примера за это время будет передано 2 мегабайта, которые и должны быть переданы повторно. Для 10Гигабитного канала этот объем увеличится до 20Мбайт. Время RTT складывается из задержки распространения электромагнитных волн по каналу и времени пребывания пакетов в очередях и их обработки в сетевых устройствах. Вторая составляющая преобладает (если это не спутниковый канал). Время распространения волны по кабелю длиной 5000 км составляет около 25 мсек, задержка в современном маршрутизаторе варьируется от 2 до 20 мсек. Число же маршрутизаторов на пути такой длины равно 10-15. Дополнительной вклад в задержку внесут переключатели локальной сети, а также системы отправителя и получателя. Таким образом, приведенное выше значение RTT является типичным, и, следовательно, нужно искать пути выхода из тупика, сопряженного с повторной передачей больших массивов данных. Можно рассматривать варианты, где исключается или сводится к минимуму вероятность потери пакета (тогда ничего повторно передавать не нужно). В некоторых моделях реализации ТСР предусмотрен режим “исключения перегрузки”, что подразумевает исключение потери пакетов. Но, к сожалению, полностью исключить потери пакетов невозможно, хотя бы из-за конечной вероятности их повреждения при транспортировке. Можно задуматься о снижении величины RTT. Это делает бесперспективным использование скоростных спутниковых каналов связи, где составляющая, сопряженная с временем распространения электромагнитных волн, составляет около 400мсек, а вероятность искажения относительно велика. Время пребывания пакета в очереди и длительность его обработки в маршрутизаторе пока сократить нельзя. Можно ли сократить число маршрутизаторов в виртуальном соединении точка-точка? Если следовать требованиям современного протокола ТСР, это сделать нельзя, так как конечные точки заданы сессией (отправитель-получатель), а промежуточные узлы - топологией Интернет и протоколом маршрутизации. Далее рассматривается принципиально новый вариант протокола ТСР, который будем называть NTCP. Все сетевые объекты, поддерживающие протокол NTCP, должны анализировать и модифицировать TCP-заголовки откликов не только адресованных им пакетов, но и всех транзитных. Для широкомасштабной реализации протокола NTCP необходима адаптация сетевых маршрутизаторов (в настоящее время они обрабатывают только IP-заголовки) и крайне желательна переделка переключателей уровня L2. Если исключить виртуальное соединение точка-точка и сделать так, чтобы виртуальный путь состоял из цепочки сегментов маршрута, то RTT можно сократить в разы, а для протяженных маршрутов на порядок. Традиционный виртуальный ТСР-маршрут превращается в цепь туннелей, соединяющих последовательные маршрутизаторы, поддерживающие NTCP. Здесь не имеются в виду IP-туннели с вложением IP-дейтограммы в IP-пакет. Примеры таких туннелей можно видеть на рис. 3 между узлами А и 1, а также между 3 и 4. Для каждого из туннелей RTT становится равным времени транспортировки и обработки пакета для одного шага, что может составлять 1-5 мсек (или даже меньше). 16-битного поля окна заголовка при RTT>5мсек хватит до скоростей передачи данных ~20Гбит/c. Можно предполагать, что для 100Гигабитного оборудования будут характерны меньшие значения RTT, что позволит во многих случаях исключить использование опции ширины окна. При потере пакета проблема улаживается локально в данном сегменте-туннеле, объем повторно пересылаемых данных будет минимальным. В случае минимизации RTT потребуется большая точность измерения этого времени (~10-100мксек). Сокращение среднего значения RTT пропорционально снизит требования, предъявляемые к объему буферов во всех сетевых устройствах по пути от отправителя к получателю. Кроме того, время определения неработоспособности канала также сократится в несколько раз. В отличие от обычного протокола ТСР (рис. 1 верх) в такой схеме взаимодействует не конечный отправитель с конечным получателем, а только отправитель с ближайшим маршрутизатором (поддерживающим протокол NTCP), соседние маршрутизаторы между собой и конечный маршрутизатор с получателем (см. рис. 1, низ; случай, когда все маршрутизаторы поддерживают NTCP). Предусматривается возможность диалога с соседним маршрутизатором на предмет проверки, поддерживает ли он NTCP. Понятно, что в этом варианте маршрутизаторы должны научиться работать на уровне L4 (сейчас они работают только на уровне L3), различать сессии, установленные между одними и теми же конечными агентами (анализировать номера портов или идентификаторы сокетов). Разбивка единого виртуального соединения отправитель-получатель на последовательность соединений соседних сетевых устройств снизит транзитный трафик, так как в случае потери пакета, повторная его транспортировка будет осуществляться лишь для одного сегмента пути (того, где произошла потеря), а не всего маршрута отправитель-получатель.
Рис. 1.
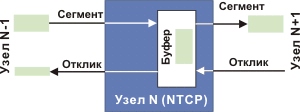
Рис. 1.а Возможны две модели реализации протокола NTCP, ориентированного на соединение. 1. Обработка сегментов уровня L4 (TCP) осуществляется не только маршрутизаторами, но и переключателями уровня L2 (рис. 1 верх). При этом они выделяют из потока сегменты-отклики и укладывают в их поле данных свой идентификатор, полную емкость буфера и уровень его заполнения на текущий момент. Это не должно создать проблем, ведь поле данных отклика свободно и там достаточно места для практически любого объема записей, характеризующих состояние буферов. Отправитель, получив такой отклик, записывает содержащиеся в нем данные, сравнивает их с ранее полученными, методом экстраполяции вычисляет вероятность перегрузки и на основании этой оценки определяет, когда следует послать очередной пакет. Данный алгоритм исключает перегрузку в принципе, хотя вероятность потери из-за порчи пакетов все равно остается. О состоянии виртуального соединения при этом исчерпывающую информацию могут иметь все участники. Если какой-то отправитель, несмотря на неблагоприятный прогноз, осуществит передачу, этот пакет будет отвергнут ближайшим маршрутизатором и не создаст проблем для сетевых устройств, расположенных за ним. Таким образом, такое “антиобщественное” поведение не будет поощрено. Напомню, что в существующих моделях ТСР допускается “агрессивное” использование ресурсов канала в ущерб остальным участникам обменов. RTT здесь будет тем же, что и в традиционном протоколе ТСР со всеми вытекающими последствиями. Но отправитель, владея полной информацией о состоянии буферов в промежуточных узлах, может делать более точный прогноз и корректно выбрать значение окна. С точки зрения выбора CWND этот алгоритм является идеальным, но требует использования усовершенствованного оборудования. Если некоторая часть оборудования не следует данному алгоритму, система будет работать, но станет возможной потеря из-за переполнения буферов в этом оборудовании, снижающая эффективность алгоритма. Следует заметить, что современная технология позволяет создать переключатели уровня L2, не только способные сообщать о состоянии очередей в своих буферах, но и реализовывать приоритетное обслуживание (DiffServ), учитывающее код DSCP в заголовке IP-дейтограммы. Разработка таких переключателей даст возможность обеспечивать требуемый уровень обслуживания для локальных сетей, что принципиально поменяет характер работы многих приложений. Структура рекорда в поле данных отклика может иметь формат, показанный на рис. 2. Число рекордов в отклике зависит от числа шагов между отправителем и получателем.
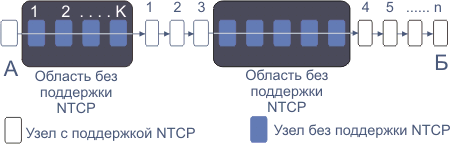
Рис. 2. В поле идентификатор может размещаться IP-адрес сетевого объекта, а в случае прибора L2 - номер по порядку или его идентификатор. Поля заполнение и полный объем буфера содержат число записанных сегментов и максимально возможное число сегментов, соответственно. Необходимость отдельной записи данных о состоянии входного и выходного буферов диктуется возможностью разной загрузки этих буферов из-за различия потоков в противоположных направлениях. Можно рассмотреть вариант, где каждому из полей (кроме идентификатора) выделяется по одному байту. Проблема может существенно осложниться, если маршруты в направлении туда и обратно отличаются (хотя такая ситуация не является типичной и свидетельствует об ошибках сетевого администратора). Тогда запись состояния выходного буфера в отклик по пути следования пакета становится бессмысленной. Нужную информацию можно получить лишь при передаче кадра данных от отправителя к адресату. Сделать алгоритм универсальным можно путем расширения поля опций заголовка (или выделением специального поля в заголовке), куда производить запись состояния буферов сетевых агентов по маршруту отправитель-адресат. Эти данные затем переносятся получателем в рекорды состояния буферов отклика. Размер MSS при этом немного сократится. Следует учитывать и возможность переполнения очередей откликами. Но так как отклики посылаются лишь на присланный сегмент, а посылка сегмента обусловлена состоянием буферов по пути следования, то правильный выбор параметров алгоритма, полностью исключит такую возможность. 2. Отклик на получение сегмента выдает ближайший маршрутизатор. В его задачу будет входить отправка сегмента очередному маршрутизатору и получение подтверждающего отклика от него. Маршрутизатор n посылает отклик подтверждения маршрутизатору n-1 немедленно, по получении сегмента. Приняв и подтвердив получение сегмента, маршрутизатор берет на себя ответственность за последующую доставку сегмента следующему маршрутизатору, и так далее вплоть до конечного адресата (см. рис. 1а). Может возникнуть вопрос, а если в этой цепочке возникнет ситуация, когда сегмент не может быть доставлен. Что произойдет? Могут быть переполнены буферы промежуточных маршрутизаторов. Но главное, как об этом узнает исходный отправитель? Поскольку виртуальное соединение строится из цепочки туннелей, IP-адрес исходного отправителя известен всем участникам, и после нескольких неудач (максимальное число их должно быть оговорено) исходный отправитель может быть уведомлен о том, что адресат недоступен с помощью ICMP-сообщения. Если отправитель продолжает передачу, это ICMP-сообщение через некоторое время дублируется. Не переданные сегменты уничтожаются. Процедура эта может быть реализована прекращением подтверждения сегментов или посылкой ICMP-сообщения своему соседу отправителю. Одновременно с этим по цепочке маршрутизаторов от заблокированного устройства в направлении отправителя будет распространяться волна неподтверждений и прерываний передачи. Можно предусмотреть специальный отклик, уведомляющий соседа-отправителя о блокировке маршрута. Алгоритм усложняется лишь в случае проблем в канале, при нормальной ситуации задержка (RTT) в цепочке отправитель-получатель минимальна. Если пакет оказался поврежден, по истечении таймаута он будет послан повторно (RTO=RTTm +4 D, как и обычном ТСР, только RTT и его дисперсия D в рассматриваемом варианте в несколько раз меньше; см. также RFC-2988). Предлагаемый протокол может быть реализован по схеме точка-точка или для части виртуального пути, например, на участке опорной сети сервис-провайдера. В последнем случае туннелирование оформляется в пограничных маршрутизаторах опорной сети (примерно также, как в случае протокола MPLS). Возможен вариант предварительного формирования цепочки туннелей, примерно так, как это делается при создании виртуального канала в ATM (см. http://book.itep.ru/4/43/atm_435.htm рис. 4.3.5.1). У такого подхода имеются привлекательные стороны, так как все участники получат исчерпывающую информацию обо всех адресах. Но и в случае разрыва связи, как в АТМ, придется формировать цепь туннелей заново. Но это неизбежная процедура в любом случае. Здесь следует рассматривать несколько фаз работы протокола и соответствующие им угрозы. 1. Установление соединения. 2. Аутентификация 3. Работа после аутентификации 4. Завершение сессии, разрыв соединения. Так как при внедрении нового протокола придется взаимодействовать с большим объемом оборудования и ЭВМ, которые этот протокол не поддерживают, необходимо на фазе установления соединения осуществлять контроль того, поддерживается протокол или нет данным сетевым объектом. При установлении соединения могут быть использованы идеи, изложенные в RFC-1644. Вначале процесса установления соединения отправитель (А) посылает дейтограмму по IP-адресу конечного получателя (Б). Ближайший к отправителю узел, который поддерживает протокол NTCP, перехватывает посланный пакет, заносит его в буфер, и немедленно посылает исходному отправителю подтверждение получения. Это подтверждение перехватывается ближайшим NTCP-маршрутизатором, уведомляя его о том, что посланный им сегмент благополучно доставлен. Этот процесс будет продолжаться до тех пор, пока дейтограмма не будет получена конечным адресатом. В результате будет сформирована цепочка туннелей с номерами i=1,…,n, каждый из которых содержит от одного до k шагов (см. рис. 3). Первый шаг на рисунке соответствует туннелю A-1, содержащему К шагов. Выигрыш в эффективности использования полосы каналов тем больше, чем больше узлов вдоль пути поддерживают NTCP (в идеале k º1). Если таких узлов вообще нет - выигрыша не будет.
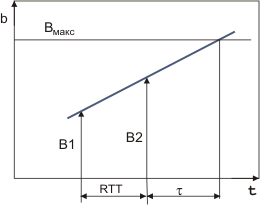
Рис. 3. Для каждого из туннелей (А-1), (1-2), (2-3), (3-4), (4-5), … и (n-1 - n) на маршруте от А до Б реализуется традиционный протокол ТСР. Если буфер в одном из промежуточных узлов оказывается близок к переполнению, он будет посылать отклики, которые уведомляют соседа-отправителя о сложившейся ситуации (это справедливо для сегментов (1-2), (2-3),. (4-5), … и (n-1 - n)). Отправитель перестанет посылать очередные пакеты. В свою очередь его сосед выше по течению (в направлении к А) может оказаться в режиме близком к переполнению и будет вынужден уведомить об этом своего предшественника. Для сегментов (А-1) и (3-4) модель работы идентична традиционному протоколу ТСР. В области узлов А и Б могут присутствовать переключатели уровня L2, не поддерживающие протокол NTCP. Но в данной схеме, так же как и во всех моделях ТСР нет механизма подавления потери пакетов из-за их искажения. Если вероятность такого искажения существенна, нужно рассмотреть возможность оптимального определения MTU (см. например, RFC-2923). Впрочем при полной информации о состоянии буферов вдоль маршрута, отправитель может легко идентифицировать причину потери. Не следует забывать о возможности “агрессивного” поведения одного из агентов по пути от А к Б. Имеется в виду игнорирование предупреждения о близости переполнения, ведь помимо узлов, показанных на рисунке, могут быть агенты, которые подключены к этим же узлам и осуществляют через них передачу данных. Обе эти проблемы не могут быть решены методами управления CWND. Но ситуация, когда партнер, которому послано уведомление о предкритическом состоянии, продолжает посылать пакеты, разрешается простым игнорированием (отбрасыванием) таких пакетов. Следует иметь в виду, что “потеря пакета” может быть связана не только с реальной потерей кадра (из-за переполнения буфера или искажения пакета), но и с потерей подтверждения получения, вызванного теми же причинами. Отправитель может знать, что буфер получателя пуст, но не получив своевременно подтверждения на посланный ранее сегмент, будет вынужден запустить процедуру медленного старта (или повторной передачи неподтвержденного сегмента). Реально это может быть объяснено переполнением, например буфера в одном из промежуточных сетевых устройств, не поддерживающих NTCP. Если k =1, потеря пакета в такой ситуации может не сопровождаться процедурой медленного старта, так как очевидно, что переполнения буфера у получателя не произошло, а потеря носит случайный характер и достаточно ограничиться повторной передачей сегмента (значение CWND сохраняется неизменным). При k>1 такая стратегия недопустима и следует использовать одну из стандартных моделей реализации протокола ТСР. При этом необходим механизм контроля наличия буферизующих сетевых устройств между двумя узлами, поддерживающими NTCP. Иными словами нужен механизм определения, равно ли k единице. Можно конечно предложить NTCP-отправителю посылать IP-дейтограммы с заданным значением TTL (например, 30). Тогда, если очередной узел, поддерживающий NTCP, получит пакет с TTL=29, то k=2. Каждый сетевой прибор, поддерживающий NTCP, должен присваивать перед отправкой полю TTL указанное значение. Беда в том, что по дороге могут быть включены устройства уровня L2, не посылающие никаких откликов (что, собственно, характерно в настоящее время для всех приборов L2) и не изменяющие значение TTL. Тогда придется использовать традиционные механизмы управления перегрузкой с помощью медленного старта. Для сервис-провайдеров, которые знают структуру своих каналов (отсутствие приборов L2), можно использовать контроль по TTL. Мониторирование TTL может быть полезно и с точки зрения безопасности (выявление ложных маршрутизаторов). Заполнение буфера получателя происходит за счет разности между входным потоком сегментов Iin и темпом обработки сегментов Iout (отправки последующим узлам).
Рис. 4. На рисунке 4 показана временная зависимость заполнения буфера (b) сетевого устройства. (b(t) + db/dt ×RTT + d) ³Вmax, то всем отправителям-соседям, которые используют данное устройства для передачи данных, должен быть послан отклик с window=0 (сигнал прекращения передачи). d - конфигурационный параметр. Выполнение данного условия делает переполнение буфера практически маловероятным. Если после получения window=0 клиент все равно посылает сегмент (“агрессивное” поведение), такой сегмент отбрасывается и в буфер не попадает, даже если там имеется свободное место. Если значение db/dt=0 или отрицательно, а уровень заполнения буфера невелик, то CWND делается равным window. Window ¹0 посылается клиентам, например, при выполнении условия b(t) < (Вmax -2d). Алгоритм управления значением CWND отправителей по возможности не должен допускать такого развития событий. При получении отклика, в котором содержится уведомление, что b(t) ³ (Вmax -2d) значение CWND должно быть уменьшено на 1 (при двух таких уведомлениях подряд - на 4 и т.д.). Стратегия может варьироваться. Так как и отправитель и получатель владеют полной информацией, можно даже ввести наказание для отправителей, нарушающих принятые правила (отбрасывание пакетов в течение заданного времени или установка window=0). В традиционной версии TCP для установления оптимального значения window предусмотрен режим медленного старта. Это делается через механизм управления CWND. Для оптимального использования канала должно выполняться очевидное условие window > RTT×B/MSS. В любой момент времени window = min(window,CWND), то есть почти всегда меньше оптимального значения. А при медленном старте CWND варьируется от 1 до максимально возможного значения, которое может быть меньше window. Связано это с тем, что ни отправитель, ни получатель обычно не владеют информацией о заполнении буферов и поиск допустимой величины window осуществляется на ощупь. В случае k=1 или в ситуации, когда все сетевые приборы вдоль пути следования выдают данные о заполнении своих буферов, ситуация меняется радикально. Если буфер свободен (b=0, что нормально в начале передачи), и RTT× B/MSS < Вmax, то реализуется значение CWND=window= RTT ×B/MSS и, тем самым, исключается этап медленного старта. Сокращение или даже исключение фазы медленного старта существенно повысит эффективность использования канала (в 1,5-2 раза). Значение RTT предполагается определенным на фазе установления соединения. Алгоритмы вычисления среднего значения RTT и величины RTO остаются теми же, что и в традиционном протоколе ТСР. Проблемы безопасности Аутентификация должна производиться в соответствии с общепринятыми способами сразу после установления соединения в процессе открытия прикладной сессии. Вообще говоря, эта процедура не должна быть частью протокола ТСР (см. также RFC-2873). На фазе аутентификации клиент и сервер обмениваются ключами, которые могут использоваться в процессе обмена в рамках протокола ТСР. Коды эти могут быть подтверждены сертификатами. На фазе 3 в поле данных отклика (или в специально выделенное поле опций заголовка) может включаться код, присланный отправителем и закодированный (одноключевая схема шифрования) получателем, так что в случае вторжении злоумышленника в разрыв соединения он сможет прервать сессию, но подменить собой клиента или сервер ему не удастся. Атака с подбором ISN станет бессмысленной. Нельзя будет реализовать и атаку с посылкой флагов FIN, RST или ICMP в пакете, посланном не одним из партнеров соединения. Получатель принимает только ключ своего непосредственного соседа, а свой ключ посылает только соседу ”вниз по течению” (в направлении узла Б). Ссылки RFC0793 Transmission Control Protocol. J. Postel. Sep-01-1981. RFC1323 TCP Extensions for High Performance. V. Jacobson, R. Braden, D. Borman. May 1992. RFC1644 T/TCP -- TCP Extensions for Transactions Functional Specification. R. Braden. July 1994. RFC2018 TCP Selective Acknowledgement Options. M. Mathis, J. Mahdavi, S. Floyd, A. Romanow. October 1996. RFC2309 Recommendations on Queue Management and Congestion Avoidance in the Internet. B. Braden, D. Clark, J. Crowcroft, B. Davie, S. Deering, D. Estrin, S. Floyd, V. Jacobson, G. Minshall, C. Partridge, L. Peterson, K. Ramakrishnan, S. Shenker, J. Wroclawski, L. Zhang. April 1998. RFC2414 Increasing TCP's Initial Window. M. Allman, S. Floyd, C. Partridge. September 1998. RFC2415 Simulation Studies of Increased Initial TCP Window Size. K. Poduri, K. Nichols. September 1998. RFC2416 When TCP Starts Up With Four Packets Into Only Three Buffers. T. Shepard, C. Partridge. September 1998. RFC2525 Known TCP Implementation Problems. V. Paxson, M. Allman, S. Dawson, W. Fenner, J. Griner, I. Heavens, K. Lahey, J. Semke, B. Volz. March 1999. RFC2581 TCP Congestion Control. M. Allman, V. Paxson, W. Stevens. April 1999. RFC2582 The NewReno Modification to TCP's Fast Recovery Algorithm. S. Floyd, T. Henderson. April 1999. RFC2873 TCP Processing of the IPv4 Precedence Field. X. Xiao, A. Hannan, V. Paxson, E. Crabbe. June 2000. RFC2883 An Extension to the Selective Acknowledgement (SACK) Option for TCP. S. Floyd, J. Mahdavi, M. Mathis, M. Podolsky. July 2000. RFC2923 TCP Problems with Path MTU Discovery. K. Lahey. September 2000. RFC2988 Computing TCP's Retransmission Timer. V. Paxson, M. Allman. November 2000. RFC3042 Enhancing TCP's Loss Recovery Using Limited Transmit. M. Allman, H. Balakrishnan, S. Floyd. January 2001. RFC3168 The Addition of Explicit Congestion Notification (ECN) to IP. K. Ramakrishnan, S. Floyd, D. Black. September 2001. RFC3390 Increasing TCP's Initial Window. M. Allman, S. Floyd, C. Partridge. October 2002. RFC3448 TCP Friendly Rate Control (TFRC):Protocol Specification. M. Handley, S. Floyd, J. Padhye, J. Widmer. January 2003. RFC3449 TCP Performance Implications of Network Path Asymmetry. H. Balakrishnan, V. Padmanabhan, G. Fairhurst, M. Sooriyabandara. December 2002. RFC3465 TCP Congestion Control with Appropriate Byte Counting (ABC). M. Allman. February 2003 RFC3517 A Conservative Selective Acknowledgment (SACK)-based Loss Recovery Algorithm for TCP. E. Blanton, M. Allman, K. Fall, L. Wang. April 2003. 1. Ю.А.Семенов “Протоколы Интернет. Энциклопедия”, Горячая линия - Телеком, М, 2001. 2. T. V. Lakshman, Upamanyu Madhow, “The performance of TCP/IP for networks with high bandwidth-delay products and random loss” Infocom ’97, апрель, 1997, IEEE/ACM Trans. Networking, V5, N3, p.336-350, June 1997. (http://www.ece.ucsb.edu/Faculty/Madhow/publications.html/) | ||