| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||
 |
 |
 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
 |
 |
 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
 |
 |
 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
Отчет по гранту РФФИ 06-07-89055 (2006г), “Исследование нового транспортного протокола NTCP и сравнение его характеристик с известными моделями традиционного ТСР”Семенов Ю.А. (ГНЦ ИТЭФ)1.ВведениеПрогресс в области разработки новых вычислительных устройств и сетевых технологий впечатляет. Только за последние 15 лет тактовая частота персональных машин выросла с 10 МГц до 5ГГц (500 раз), а пропускная способность сетей с 10 Мбит/с до 100 Гбит/с (10000 раз). Но не за горами некоторые принципиальные ограничения, например, постоянная времени поляризации диэлектрика равна 10-13сек, что устанавливает верхний предел на тактовую частоту любых операций на уровне ~1012 Гц (ТГц). Трудно себе представить, что человечество смирится с ограничениями вычислительных возможностей. Одним из путей решения проблемы – параллельное выполнение большого числа операций и распределенная структура вычислительной системы. Такие технологии уже используются, например, при построении Ethernet-интерфейса для скорости 10 Гбит/сек (смотри Fast Ethernet (FE), GE, 10GE и 40GE). Намечается тенденция применения распределенных вычислительных систем, распределенных информационных систем и распределенных систем управления. Как правило, это различные варианты GRID, которые требуют достаточно высоких пропускных способностей от каналов. В некоторых случаях такие функции могут выполнять Р2Р-системы. Жесткие требования к полосе пропускания и качеству обслуживания стимулировали исследования в этих областях. В случае ограниченной полосы пропускания, задержка сети не является критической; тогда как, в случае широкополосных каналов сеть не может функционировать эффективно. TCP-отклики работают хорошо при малых значениях (RTT) и узкополосных каналах. Эта технология была разработана и оптимизирована для ЛВС или узкополосных WAN. Ограничения TCP в широкополосных каналах при большом RTT хорошо описаны в [2-4, 12]. Практика показывает, что коммутация пакетов – неэффективное решение для приложений с интенсивным информационным обменом. Важной характеристикой информационного канала является его реактивность. Реактивность характеризуется временем, которое необходимо для восстановления пропускной способности системы после потери одного пакета. Отбрасывание пакетов является механизмом обеспечения балансировки обменов с точки зрения QoS в сетях с коммутацией пакетов. Такой механизм встроен в протокол TCP для управления перегрузкой. Например, 15 лет назад, в LAN с RTT = 2ms и 10Mbs, реактивность была около 1.7ms. В настоящее время для 1Гбитных LAN с RTT порядка 2ms, реактивность составляет около 96ms. В среде WAN, RTT очень велико, например, RTT для канала CERN-Чикаго равно 120ms, а до Токио - 300ms. В этих случаях реактивность может достигать часа. Это связано с тем, что в случае потери пакета в протоколе ТСР запускается процедура медленного старта. Сначала CWND растет экспоненциально, затем линейно [11]. По этой причине, несмотря на улучшение BER, для каналов с большими информационными потоками приходится думать о внедрении новых транспортных технологий или значительной модификации существующих. В экспериментах OptIPuter, использовавших канал между Чикаго и Амстердамом получена полоса пропускания 4.36Мбит/c, при использовании немодифицированного протокола TCP. Новый протокол, базирующийся на UDP, показал полосу пропускания 700-920Мбит/c. Выделенные каналы для немодифицированного протокола TCP характеризуются 1% использования полосы по сравнению с 92% для нового UDP. В выделенных оптических каналах не возможно совместное использование, и, следовательно, проблема справедливого использования полосы не встает. Здесь нет конкуренции за использование ресурсов сети, а справедливое распределение ресурсов возможно за счет предварительного резервирования и диспетчеризации. По этой причине реактивность не представляет никакой проблемы. Но такое положение реализуется достаточно редко. Проблема эффективного использования канала особенно остро стоит в случае GRID. Много новых протоколов было разработано, чтобы устранить проблему сетевых ограничений, среди них - GRIDFTP [1-3], FAST [5], XCP, Parallel TCP, и Tsunami, SABUL/UDT [4]. Эти исследовательские проекты, наряду с другими подобными работами обеспечили улучшение основных транспортных механизмов, гарантируя эффективное использование широкополосных каналов пропускания. Улучшения в этих протоколах достигнуты за счет трех механизмов:
GRIDFTP может реализовать примерно 90% используемого гигабитного канала при обмене память-память (27 Гбит/c [1]). В ИТЭФ в настоящее время исследуется новый протокол NTCP, который может существенно поднять эффективность использования каналов сервис-провайдеров, так как в нем предусматривается контроль заполнения всех буферов вдоль пути следования [10]. Можно ожидать заметного увеличения эффективности распределенных систем в случае применения управления QoS. Это позволит приоритетным информационным потокам получить в нужный момент необходимую полосу пропускания [11]. Сочетание современных алгоритмов повышения эффективности использования канала с технологиями обеспечения качества обслуживания может существенно улучшить эксплуатационные характеристики распределенной вычислительной системы. Информационный трафик TCP по оптической сети через Атлантический океан составляет 20Mbs. Новые транспортные протоколы были предложены, чтобы улучшить TCP. [1, 2, 13]. Механизмы управления передачей при скорости 1Mбит/c и при скоростях порядка 10Гбит/c сильно отличаются. Сказывается отличие на 4 порядка по скорости. Когда осуществляется работа с потоками в диапазоне 1-100 Mбит/c, можно реализовать некоторые оптимизации протокольного стека. Однако, когда поток увеличивается на 4 порядка, стек протоколов и реализации приложений могут существенно замедлить процесс транспортировки информации. Новые скорости передачи требуют нового стека протоколов и новой архитектуры приложений. Одним из решений проблем для GRID может быть протокол UDDI (Universal Description, Discovery, and Integration). UDDI – стандартный протокол описания Web-сервисов и их поиска. Реестр UDDI может содержать метаданные для любых видов сервисов, вместе с вариантами «наилучшей практики», уже определенными для сервисов, описанных с помощью WSDL. За счет разбиения Web-сервисов на группы, взаимодействующие с категориями и бизнес процессами, UDDI способен более эффективно искать Web-сервисы. Спецификация UDDI определяет иерархическую схему XML, что обеспечивает модель для анонсирования, проверки и вызова информации о Web-сервисах. Выбор пал на XML, так как его формат представления данных не зависит от платформы и отражает иерархические взаимосвязи. В UDDI используются технологии, основанные на общих Интернет протоколах TCP/IP, HTTP, XML и SOAP. Существует 2 вида UDDI реестров: публичные UDDI реестры – служащие точками сбора различных бизнесов, для уведомления об их сервисах, частные UDDI реестры, которые делают то же самое, но для организаций. Еще большие преимущества в некоторых режимах обмена может дать протокол NTCP. Использование параллельных каналов данных, применительно к независимым TCP сессиям, отражается в более высокой средней величине пропускания за одну TCP сессию, чем в сетях со стандартным уровнем потерь (BER). Была сделана попытка количественно оценить разницу в полосе пропускания при трех простых предположениях: отправитель всегда имеет данные для отправки, издержки расщепления и объединения потоков для множественных сессий пренебрежимо малы, и оконечные системы имеют неограниченную полосу входа/выхода. В 2007 году в рамках данного проекта в ИТЭФ проводились следующие работы:
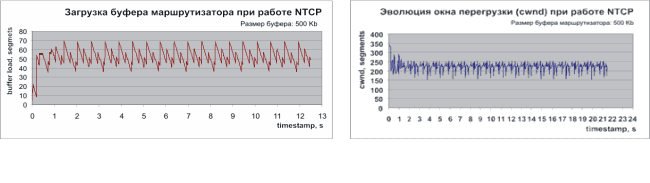
Раздел 1. Измерения рабочих характеристик тестовой сети для протокола NTCPОсновными особенностями протокола NTCP является передача с помощью откликов (ack) состояния всех промежуточных сетевых устройств, а также локальное подтверждение получения данных, исключающее повторные пересылки вдоль всего транспортного канала (см. [1]). Локальное подтверждение при определенных обстоятельствах позволяют также быстро выявить и обойти узкие участки маршрута. Для демонстрации работы протокола NTCP была собрана тестовая сеть, изображенную на рис. 1. Поток входного канала маршрутизатора был сделан больше выходного. Это неизбежно вызвало бы перегрузку буфера маршрутизатора при работе обычного протокола TCP. При измерениях использовались драйверы ОС LINUX, реализующие версию протокола ТСР-RENO. Для анализа характеристик протокола NTCP были написаны и отлажены соответствующие драйверы, реализующие данный протокол (NTCP). Кроме того, пришлось реализовать драйвер, воспроизводящий работу маршрутизатора, как в рамках традиционных протоколов, так и при работе с протоколом NTCP. Принципиальным отличием в режиме работы маршрутизатора для поддержки протокола NTCP является необходимость записи в пакет отклика (ack) получателя уровня заполнения буферов маршрутизатора. В качестве маршрутизатора использована машина с двумя сетевыми интерфейсами. Для достижения режимов перегрузки в драйвере маршрутизатора использован алгоритм маркерного ведра, гарантирующий фиксированную скорость передачи (1Мбит/c). Для оценки корректности работы системы была получена и запрограммирована рекуррентная формула для расчета временной зависимости значений окна перегрузки (CWND) и уровня заполнения буфера маршрутизатора (для протокола NTCP). При работе нашего протокола отправитель получал информацию о динамике загрузки буфера в сегментах подтверждения и, анализируя эти данные, варьировал темп передачи так, чтобы не допустить перегрузки буфера. 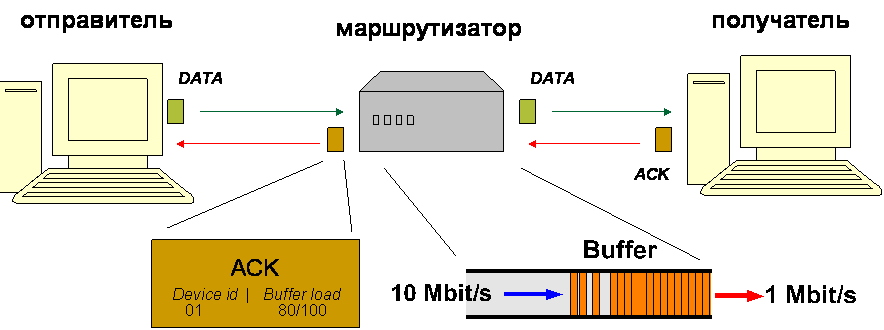 Рис. 1. Схема тестовой сети для исследования характеристик протокола NTCP Тестовая сеть, на которой проводились измерения, состоит из отправителя, получателя и установленного между ними маршрутизатора. Все три узла имеют модифицированные модули NTCP. Каждый из узлов реализован на PC и ОС LINUX. Для создания перегрузки полоса маршрутизатора на выходе (Bout) ограничивается таким образом, чтобы она была меньше входной полосы (Bin). Для проведения наших измерений мы установили Bin = 10 Мбит/с, а Bout = 1 Мбит/с. В результате измерений были получены следующие временные зависимости (для протокола NTCP):
Для сопоставления характеристик NTCP со стандартной моделью работы протокола TCP были проведены измерения для драйвера, поддерживающего модификацию протокола TCP-Reno (см. рис. 4 и 5). TCP-Reno одна из наиболее продвинутых современных модификаций протокола ТСР (см. Протокол ТСР). Результаты работы TCP-Reno представлены на рис. 4. 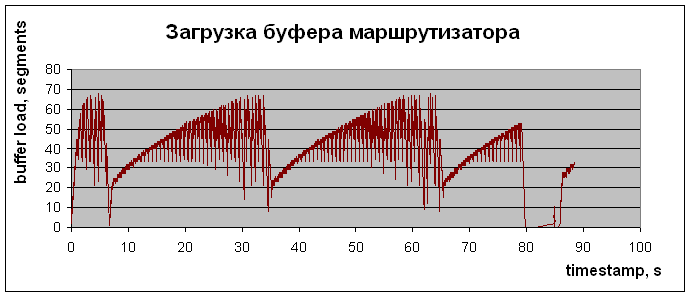 Рис. 4. Эволюция заполнения буфера для случая реализации в тестовой сети модификации транспортного протокола TCP-RENO 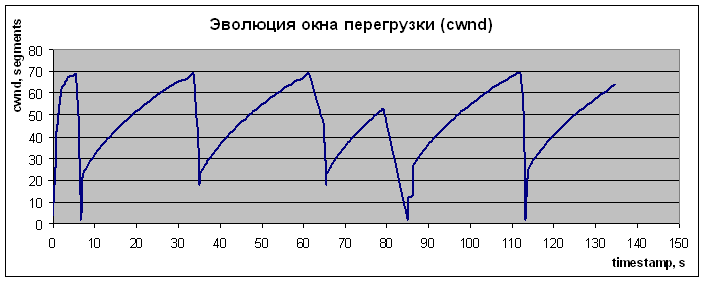 Рис. 5. Временная зависимость CWND для случая реализации ТСР Зависимости на рис. 4 и 5 демонстрируют последовательность медленных стартов (пилообразные зависимости со сбросами значений CWND), что понижает эффективность использования канала и увеличивает время восстановления канала (реактивность) при больших произведениях B?RTT (B- ширина полосы канала, а RTT – Round Trip Time). Это становится особенно важно при B > 1 Гбит/с. Из рис. 2,3 и 6,7 видно, что перегрузки маршрутизатора действительно не возникает (при размере пакета ~1500 байт максимальная загрузка держится на уровне 70?1500 ~ 100 Кбайт, а размер буфера 500 Кбайт), однако происходят достаточно большие осцилляции размера окна перегрузки. Важно, что здесь не происходит потери пакетов и медленных стартов. Окно перегрузки (Congestion window, CWND) – основной параметр, определяющий темп передачи данных отправителем, и поэтому его осцилляции являются нежелательными, т.к. это снижает средний темп отправки данных. Осцилляция связаны с задержкой обратной связи управления. Осцилляции для таких систем типичны, важно, чтобы эти осцилляции не приводили к деградации характеристик канала. В реальном Интернет такие осцилляции наблюдать трудно, так как на заполнение буферов и вероятность потери пакета влияют случайные составляющие трафика, следующего через маршрутизатор. Распределения таких компонент трафика варьируются в широких пределах, что маскирует осцилляционные вариации заполнения буфера и CWND. Выбранные варианты исследования эволюции эксплуатационных характеристик канала позволяют выявить базовые зависимости и причины вариаций CWND в разных условиях. Для исследования причины этих осцилляций и возможного уменьшения их амплитуды был создан программный эмулятор (модель) протокола NTCP, позволяющий моделировать изменения всех основных параметров NTCP (см. рис. 6 и 7). При реализации протокола NTCP важно как можно точнее предсказать зависимость заполнения всех буферов вдоль пути следования трафика. Нами использовалась линейная и квадратичная экстраполяции. От точности этого предсказания зависит эффективность работы протокола. Если прогноз занизит уровень заполнения буферов в одном из узлов по пути следования, может произойти переполнение и потеря пакета. Но даже в этом случае значение CWND не будет сбрасываться до 2. При этом значение CWND будет понижено с учетом предшествующего прогноза и зарегистрированного темпа заполнения буфера. Алгоритм NTCP позволяет с высокой вероятностью разделить случаи потери пакета из-за его повреждения и из-за переполнения буфера. В любом случае повторно будет переданы только реально потерянные пакеты. 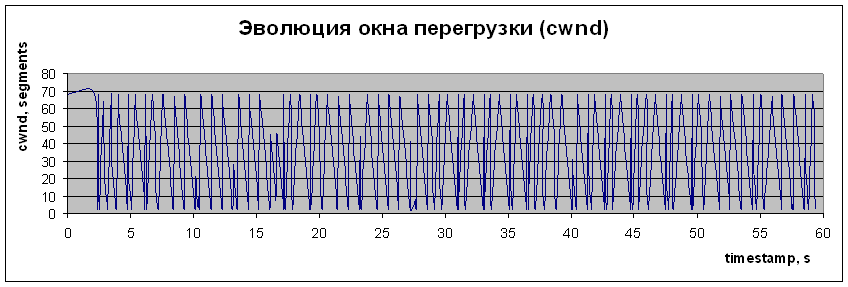 Рис. 6. Временная зависимость значения окна перегрузки (CWND) 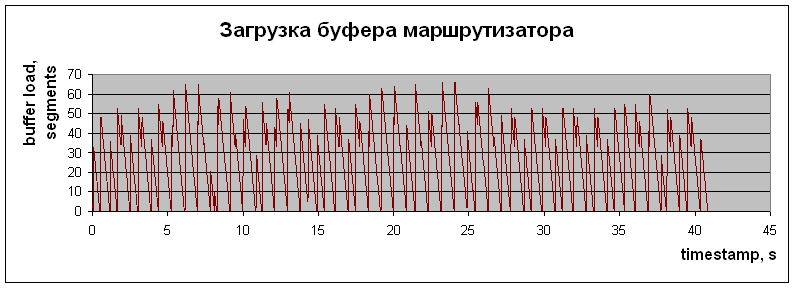 Рис. 7. Временные вариации заполнения буфера 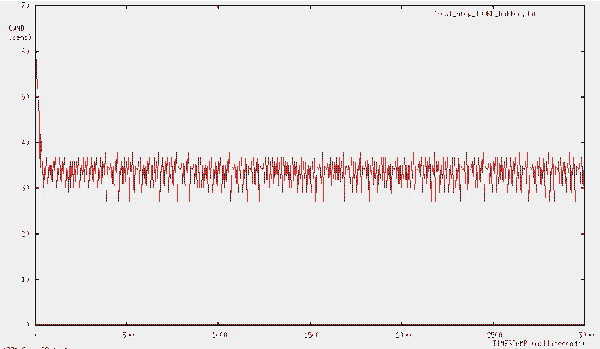 Рис. 8. Вариация CWND для буфера 100кбайт при подтверждении каждого второго полученного пакета и при выходной полосе 1 Мбит/c 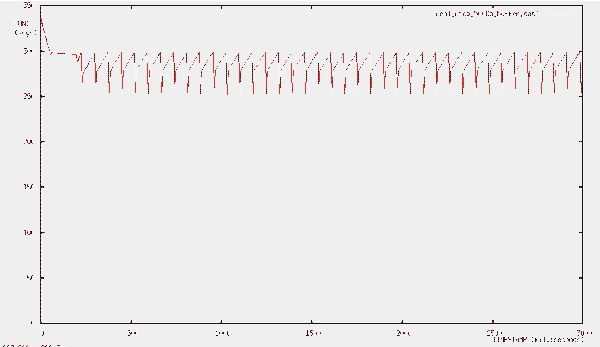 Рис. 9. Вариация CWND для буфера 500 кбайт при подтверждении каждого второго полученного пакета и при выходной полосе 1 Мбит/c Специфика алгоритма NTCP такова, что осцилляции CWND в данной тестовой установке возникают из-за обратной связи (увеличилась загрузка буфера – уменьшилось CWND, уменьшилась загрузка буфера – увеличилось CWND). Таким образом, система "Загрузка буфера – размер окна CWND" представляет собой автоколебательную систему с задержкой. Задержка проявляется в том, что отправитель получает информацию о загрузке буфера спустя < RTT (в среднем ~RTT/2). С помощью эмулятора NTCP мы исследуем параметры этой автоколебательной системы и попытаемся определить, какие изменения алгоритма нужно сделать для уменьшения осцилляций окна перегрузки. Раздел 2. Использование нитей (threads) для моделирования работы протокола TCPДля исследования работы протокола TCP и разработки его модификации была создана модель этого протокола в виде исполняемой программы под Linux. Целью создания этой модели является отслеживание различных параметров соединения TCP при передаче данных. Эта элементарная модель состоит из модуля-отправителя, модуля-получателя и модуля, обрабатывающего подтверждения (маршрутизатор). По очевидным причинам эти модули должны работать независимо друг от друга, — хотя бы потому, что они эмулируют работу составляющих «частей» TCP, находящихся в реальной сети на физически разных компьютерах. Поскольку нас интересовало только изменение параметров TCP, в модели не было необходимости передавать реальные пакеты с данными между этими модулями – достаточно было сымитировать только поведение необходимых нам параметров согласно алгоритму передачи данных в TCP. 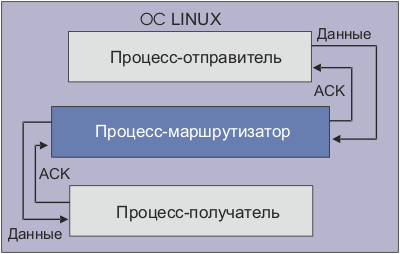 Рис. 10. Система моделирования поведения протокола NTCP в различных режимах работы Физическая система, которую мы моделируем с помощью нашего симулятора, состоит из компьютера-отправителя, компьютера-получателя и расположенного между ними маршрутизатора. Интересующие нас параметры – это, прежде всего, эволюция окна перегрузки отправителя (congestion window - CWND) и эволюция загрузки буфера маршрутизатора. Для реализации данной задачи в среде Linux легче всего воспользоваться способами межпроцессного взаимодействия (Linux IPC), либо механизмом нитей (Posix threads). В качестве более удобного и простого в реализации способа мы выбрали последний. Таким образом, каждый модуль нашего симулятора представлял собой отдельную нить. Как известно, в Linux все нити в контексте одного процесса имеют общую память, а для совместного доступа к этой памяти используется механизм взаимных исключений (MUTual EXclusion, mutex). Общая идея взаимных исключений заключается в том, что нить, которая использует определенную часть общей памяти, блокирует доступ к ней других нитей, которые, в свою очередь ждут освобождения этого ресурса. В качестве примера приведем часть кода нашей модели с реализацией подобной схемы при доступе к переменной, отражающей размер окна перегрузки отправителя: // необходимо для использования нитей // компиляция с ключом -lpthread #include Каждый модуль нашей модели выполнял бесконечный цикл, в котором производились необходимые действия с TCP-параметрами. К примеру, цикл в send_thread «отправлял» пакеты (вернее, не отправлял, а увеличивал на 1 переменную sent – количество отправленных пакетов, и переменную buffer_load – загрузку буфера маршрутизатора). Однако в TCP отправка пакетов происходит только в случае, если это позволяет сделать механизм скользящего окна – грубо говоря, количество пакетов, отправленных без ожидания подтверждений, ограничено. Для этого мы воспользовались механизмом условных переменных (Conditional Variable). В нашем конкретном случае пакет отправлялся только в случае, если переменная may_send больше 0. Если же при очередной итерации цикла обнаружилось, что may_send = 0, нить останавливается и ожидает, когда это значение увеличится, и только тогда происходит «отправка» пакета. Переменная may_send также представляет собой mutex-переменную, которая рассчитывается каждый раз при получении подтверждения, т.е. в нити ack_receive_thread(). Пример использования may_send в качестве условной переменной в функции send_thread: void *send_thread(void *arg) {
while(1) {
// блокировка may_send
pthread_mutex_lock(&may_send.mutex);
// ожидание, когда may_send станет больше 0
// при выполнении функции pthread_cond_wait переменная may_send
// разблокируется для того, чтобы другие нити могли изменять ее
while(may_send.value <= 0)
pthread_cond_wait(&may_send.cond, &may_send.mutex);
may_send.value--;
// разблокировка may_send
pthread_mutex_unlock(&may_send.mutex);
// теперь можно «отправлять» пакет
// увеличиваем загрузку буфера
pthread_mutex_lock(&buffer_load.mutex);
...
buffer_load.value++;
...
pthread_mutex_unlock(&buffer_load.mutex);
// увеличиваем значение sent
pthread_mutex_lock(&sent.mutex);
sent.value++;
pthread_mutex_unlock(&sent.mutex);
...
}
}
В свою очередь, функция ack_receive_thread(), которая пересчитывает значение may_send каждый раз при приходе подтверждения, сигнализирует остальным нитям о том, что значение may_send, возможно, изменилось: void *ack_receive_thread(void *arg) {
...
while(1) {
...
// блокируем необходимые для расчета may_send переменные
pthread_mutex_lock(&cwnd.mutex);
pthread_mutex_lock(&acked.mutex);
pthread_mutex_lock(&may_send.mutex);
pthread_mutex_lock(&sent.mutex);
// если другие нити ожидают изменения may_send, сигнализируем
// им об этом
if(may_send.value == 0)
pthread_cond_signal(&may_send.cond);
// рассчитываем may_send
may_send.value = acked.value + cwnd.value - sent.value;
if(may_send.value < 0)
may_send.value = 0;
// разблокируем переменные
pthread_mutex_unlock(&sent.mutex);
pthread_mutex_unlock(&may_send.mutex);
pthread_mutex_unlock(&acked.mutex);
pthread_mutex_unlock(&cwnd.mutex);
};
}
Раздел 3. Аналитическое моделированиеДля моделирования загрузки буфера использовалась итеративная формула: buf_load(i+1)= buf_load(i) + min(cwnd(i) - buf_load(i), in_bwidth/out_bwidth) - 1 Для описания эволюции окна перегрузки применена итеративная формула: cwnd(i+2) = buf_size - 2 * buf_load(i) + buf_load(i-2); итерация i соответствует приходу пакета получателю. Поскольку подтвержда-ется каждый второй полученный пакет, cwnd вычисляется в 2 раза реже, чем buf_load. Если при расчете CWND оказывается, что 2*buf_load – buf_load(i-2) > buf_size, то CWND определяется из соотношения: cwnd(i+2) = cwnd(i) -2 Эволюция CWND рассчитанная по приведенным выше формулам для размера буфера 100 кбайт представлена на рис 11. 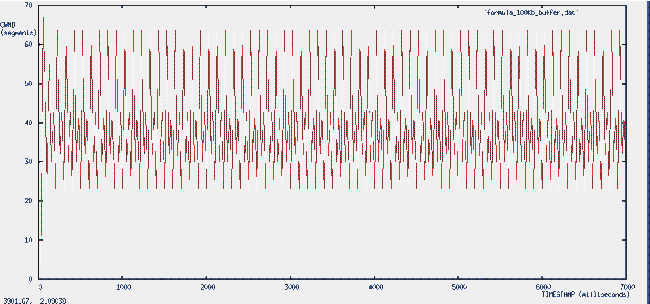 Рис. 11. Эволюция CWND 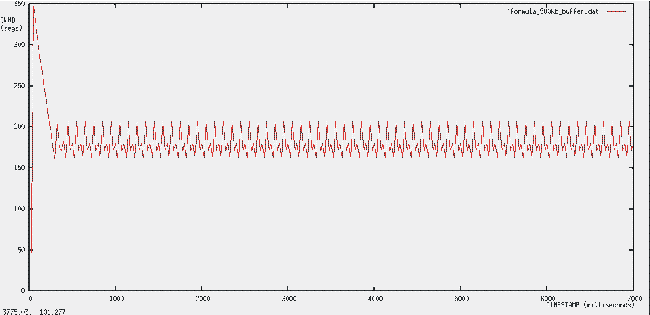 Рис. 12. ЭЭволюция CWND для размера буфера 500 кбайт Основные публикации по результатам данных исследований (не менее 3 статей) планируются в текущем году. Протокол NTCP описан во втором томе трехтомника “Алгоритмы телекоммуникационных сетей" [11] вышедшем в 2007 году. Выводы
Ссылки
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||